Some thoughts on the environmental impact of High Performance Computing
2022-10-26
- 1. Energetic sobriety
- 2. The global carbon impact of computation
- 3. Low-carbon electricity is not a silver bullet
- 4. HPC efficiency
- 5. Rebound effects
- 6. Computation sobriety: when less is more
- Bibliography
This article was originally published as part of my Habilitation à Diriger les Recherches [1].
Faced with an unprecedented climate crisis, reducing our environmental impact is paramount. HPC’s direct effects on the environment are twofold.
First, producing HPC hardware involves complex industrial processes and depends on costly resources such as rare-earth elements. Large areas are mined to extract rare-earth elements with major ecological and health impacts. Mining releases toxic and radioactive materials that poison the land and the people around the extraction sites. Moreover, rare-earth mines operate in developing countries where the labor cost is low and environmental regulations are less strict, leading to human rights abuses and child labor to satisfy the demands of the high-tech industry. Disposing of obsolete HPC hardware is also problematic, and waste is often exported to developing countries. For example, the Agbogbloshie district in Ghana has become one of the largest dumps where electronic waste is dismantled under unsafe conditions with harmful health [2] and environmental effects.
Second, HPC requires energy to fabricate the hardware and perform the computations, which translates into greenhouse gas emissions, particularly carbon dioxide emissions. Reducing these emissions is critical to mitigate global warming.
However, HPC also has indirect effects on the environmental crisis. The technological advances it brings can cause rebound effects where the efficiency gained increases demand for computation. Paradoxically, the increased demand can result in a net increase in carbon emissions and new hardware manufacture, worsening the ecological impact.
My research has focused on optimizations at the compiler, operating system, and software levels. Therefore, in this survey, I look at the environmental impact through the prism of power consumption and the associated carbon emissions. This choice is guided by my research field and does not imply that the other topics, such as rare-earth extraction, are less important.
One could think that optimizations reducing the computation cost of a code also improve the power consumption. Instead, the gained efficiency often amortizes an increase in the computation size or the simulation complexity. In that case, the larger problem size offsets the gained efficiency, and the net effect is that the power consumption stays the same or even increases.
The climate crisis is shifting the focus to reducing energy consumption and limiting the environmental impact of computations. Improving the computation efficiency might not be enough and could even be counterproductive because of rebound effects. I think more sobriety in our computation demands is required; in particular, instead of pushing for larger and more complex models, we should aim for the smallest model satisfying the required accuracy.
Energetic sobriety
We are in the midst of an ecological crisis, documented extensively by the scientific community [3]. One major aspect of this crisis is global warming, which calls for a drastic reduction of our carbon footprint. The Stratégie Nationale Bas Carbone is the French national roadmap for reaching carbon-neutrality in 2050; its last revision in 2020 operates under the hypothesis that France will reduce its energy consumption by 40% either through increased efficiency or sobriety. In this context, improving energy efficiency is paramount when optimizing HPC programs and architectures.
The TOP500 and Green500 lists have ranked the computing and power efficiency of the top supercomputers. In 2013, the most efficient supercomputer in these lists achieved 3208 MFlop/s/W; in 2022, the most efficient supercomputer achieved 39.4 GFlop/s/W. In a decade, the energy efficiency has been multiplied by 12. Efficiency improvements result from improvements in chip manufacturing technology, the use of specialized accelerators, and careful optimization of applications.
However, this efficiency improvement comes with a comparable increase in computation capacity. The total computing capacity of the TOP500 list has gone from 228.6 PFlop/s in 2013 to 3 EFlop/s in 2022, representing a 13 times increase in computing capacity.
When considering the net carbon impact of HPC, the efficiency savings are lost due to the increased computation demand. One might wonder whether HPC is subject to rebound effects (discussed in section 5), where the efficiency gained in a technology fosters its widespread adoption, nullifying the net energy savings.
Another option to reduce HPC’s power budget is to compute less. Often, the trend is to reach for the more complex and fine-grained models available, which come with an increased computation cost. But we should not aim for the most precise and accurate computation when a simpler or less precise model would do the job. For example, reducing the floating-point precision of a model can save computation and energy [1].
The global carbon impact of computation
Most studies that evaluate the carbon impact of computation do not specifically focus on HPC centers but consider the broader ecosystem of data centers which, besides high-performance computations, also runs data-oriented internet services.
Data centers worldwide use an estimated 200TWh [4] each year, representing 1% of the global energy demand and 0.3% of the global carbon emissions. That figure is under-estimated because it does not account for the embodied emissions [5] of data centers: the carbon emitted to fabricate the servers and their surrounding infrastructure.
When personal digital devices, mobile phone networks, and televisions are also included, the whole information and communication technology (ICT) carbon footprint is estimated to be 1.8%-2.8% of the global carbon emissions [6]. Embodied emissions are important in the ICT sector: they represent 23% of the total carbon impact. In France, the part of embodied emissions is even higher because the carbon intensity of French electricity is low. Therefore, besides reducing computations, it is essential to prolong the lifetime of ICT appliances.
A 1.8%-2.8% total carbon footprint for ICT might appear unimportant. In particular, when compared to the carbon emitted by the industry (29.4%), transportation (16.2%), or residential sectors (10.9%) [7]. Nevertheless, it should be put into perspective since the demand for HPC, particularly AI, is growing quickly; for example, it is estimated that DNN computations have increased by a 300 000 factor from 2012 to 2018 [8].
While this discussion focuses on carbon impact to keep matters simple, as mentioned in the introduction, ICT raises other important sustainability issues such as rare-earth mining and electronic waste.
Low-carbon electricity is not a silver bullet
To mitigate the carbon impact, some computation-centers buy renewable energy on the grid [9] or are built close to renewable energy sources such as geothermic plants. Others perform their computations when the demand on the grid is low, reducing their operation cost since they buy the electricity at a premium price and optimize the usage of the grid scheduling computation when there is a surplus of electricity.
Despite these strategies, Freitag et al. [6] conclude renewable energies are not a silver bullet due to their limited availability with current technology. They note that renewable energy is a scarce resource and that any energy taken by ICT will not be available for other uses.
The carbon intensity of electricity in France is low, in 2021, the annual average was 36 gCO2/kWh, as reported by Réseau de Transport d’Électricité (RTE). Indeed, 92% of french electricity comes from low-carbon production methods: 69% comes from nuclear power plants, 12% from hydroelectric power stations, 7% from wind turbines, and 3% from solar panels. Nevertheless, only 25% of the French final energy consumption comes from electricity. Fossil fuel’s annual energy consumption was 1005TWh in 2021, which represents 61% of the final energy mix.
Due to the low carbon intensity of electricity, some argue that reducing computing energy consumption in France will not significantly lower the national carbon footprint and advocate focusing on decarbonating other sectors such as transport or heating, which depend mainly on fossil fuels. Yet, moving to electric heaters and cars will increase the required electricity budget drastically. Satisfying such an increase in electricity demand is impossible with the current electricity production infrastructure and scaling the renewable and nuclear production is a complex challenge [10] with multiple technological uncertainties. Given the forecasted growth of the ICT sector, reducing ICT energy consumption appears necessary to free renewable electricity for decarbonating heating, transport, or other essential industries.
Many countries still depend massively on fossil fuels for their energy production. For example, in 2021, US carbon intensity was 379 gCO2/kWh, ten times more than France. The world average carbon intensity in 2021 is 442 gCO2/kWh. The low carbon intensity in France is the exception and not the rule.
HPC efficiency
Dennard’s scaling: 1970-2009
From 1946 to 2009, the power efficiency of processors doubled every 1.57 years [11]. This efficiency gain was achieved mainly through improvements in the lithographic and chemical manufacturing process of semiconductors, which reduced the gate length of transistors in each generation of processors.
Current logic circuits use Complementary Metal Oxide Semiconductor (CMOS) transistors. The power consumption of a CMOS gate is modeled by two terms representing the dynamic and static power, respectively, \(P = \underbrace{1/2.C.V^2.f}_{P_\textrm{dynamic}} + \underbrace{V.I_{\textrm{leak}}}_{P_\textrm{static}} \label{c8:eq:power}\) where C is the equivalent charge capacity of the gate, V the voltage applied to the gate, f the clock frequency of the gate double-transitions (rising and falling), and Ileak the intensity of the leak currents.
In 1975, Dennard observed that for each new transistor generation, the transistor dimensions were reduced by 30% through manufacturing improvements.
This has the following implications:
-
The voltage and capacitance also diminish by 30% since they vary linearly with the transistor size.
-
The propagation time diminishes by 30% since the distance is reduced and the frequency grows by 42% since it varies inversely to the propagation time.
-
The surface area is reduced by 50% ≈ 0.7 × 0.7.
Given these changes, Pdynamic should be roughly halved in each new transistor generation, \(\Delta P_\textrm{dynamic} = \Delta C.\Delta V^2.\Delta f = 0.7\times 0.7^2 \times \frac{1}{0.7} \approx 0.5\)
Assuming that the static power is small, the power dissipation per surface unit remains constant across CPU generations. Indeed, the surface is halved for each generation, but so is the power dissipation.
In practice, CPU manufacturers have used the surface gain to double the number of transistors in each generation and because the frequency also increases by 42%, the computing efficiency in FLOPS/W has improved across generations.
These observations, called Dennard’s scaling, were empirically verified from 1970 to 2009. However, the rate of scaling has started slowing since 2009. The main reason is that with the continuing miniaturization of transistors, leak currents increase, which in turn increases the static power limiting the miniaturization of transistors and efficiency scaling [12].
Multi-Processing and accelerators: 2009-2022
Because frequency scaling has reached a limit, chip manufacturers turn to other strategies to improve FLOP/s. We have seen two main trends in this last decade. First, manufacturers have started increasing the number of processing elements per socket. For applications that expose enough fine-grained independent tasks, massive parallelism improves the performance despite the frequency limit. Second, there is increased usage of specialized processors such as GPU (Graphical Processing Units), TPU (Tensor Processing Units), FPGA (Field Programmable Gate Arrays). These processors target massively parallel applications where tasks are mostly synchronous and execute the same operations. They excel in specific domains such as dense linear algebra computations, machine learning, crypto-currencies mining, and others. Specialized processors tailored to a particular application domain can achieve impressive performance and often better power efficiency.
In this decade, power efficiency in computing elements has continued to improve due to technological advances and reductions in idle power. Efforts have also been made to optimize the other components in an HPC system, such as memory, storage, network interfaces, or power converters. The top two machines in the Green500 list for November 2021 illustrate the previous trends. The first supercomputer, MN-3, achieves 39.38 GFlops/W with 1 664 MN cores, specialized chips for matrix arithmetic. The second supercomputer, SSC-21, achieves 33.96 GFlops/W with 16 704 AMD EPYC 7543 cores. In recent years, AMD has significantly improved the power consumption [13,14] of general-purpose CPUs.
As discussed in section 1, when comparing the most efficient supercomputers between 2013 and 2021, we see a 12× improvement in power efficiency. This trend is also true for internet data centers, Masanet et al.[15] shows that, in the last decade, server efficiency has improved owing to more efficient CPUs, storage-drive density and efficiency gains, better server utilization thanks to virtualization, and better data-center power usage effectiveness.
Software optimizations
Current processors offer multiple idle modes. For example, Intel processors have different P-States and C-States. In P-States, the CPU is active but operates in a power-saving mode. C-States are sleep modes, which turn off parts of the system, deep C-States offer substantial energy saving during idle time, but there is a transition delay from P-States to C-States to wake up the processor.
P-States are based on DVFS (Dynamic Voltage Frequency Scaling) [16]: voltage and frequency are reduced to decrease the static and dynamic power. P-States are either changed by the operating system or runtime governors [17] or are directly managed by the hardware itself, depending on the workload. For some HPC applications, DVFS can achieve up to 16.5% [18] energy savings without significantly reducing their performance. The key idea is to reduce the frequency and voltage during the less computation-intensive phases or selectively reduce them for the uncore components [19].
On the application side, many factors affect the energy efficiency such as the choice of the algorithm and the data structures. The language, optimization, and compiler also impact the energy used. In general, compiled languages tend to be more energy-efficient [20] than interpreted languages. Yet, many factors are at play, and one should be careful when comparing languages since the results depend on the developers’ implementation and expertise.
Often, optimizations that improve the performance also improve energy saving. Since the energy consumed is the product of the power and the computation time, reducing the computation time shrinks the energy product. In some corner cases, optimizations for energy and execution time are different, but on most platforms, the optimizations improving execution time also improve energy [21]. For this reason, the LLVM Compiler does not offer a specific optimization level targeting energy.
Rebound effects
In 1865, the economist William S. Jevons observed that Watt improvements of the steam engines’ efficiency was accompanied by an increase in coal consumption. Watt’s engine efficiency fostered its adoption by a wide range of industries. Jevons paradox, also called the rebound effect, states that an increase in efficiency in resource use will generate an increase in resource consumption rather than a decrease.
Gossart[22] reviews the literature on rebound effects of ICT. He distinguishes different levels of rebound effects.
-
Direct rebound effects increase the spread of ICT technologies.
-
Indirect rebound effects happen when increasing ICT efficiency reduces the cost of goods or services produced with ICT. This indirect cost reduction increases the consumption of other resources.
-
Economy-wide rebound effects structurally change production and consumption patterns, potentially increasing production and associated carbon emissions in other fields.
As previously seen in section 4, from 1970 to 2009, the power efficiency of processors doubled every 1.57. Nevertheless, Hilty et al. [23] show that in the same period, the computation power for personal computers doubled every 1.5 years. Moreover, the number of installed computers doubled every three years from 1980 to 2008. The increase in computation demand offset efficiency gains. The continuous improvements in chip manufacturing cost and frequency lead to quick obsolescence of old slower models and an explosion in demand. This is an example of a direct rebound effect in CPUs.
For HPC, the 12 × efficiency improvement achieved between 2013 and 2022 is shadowed by a 13 × computation power increase. Figure 1 confirms this trend by looking at the evolution of the first 100 systems in the TOP500 supercomputer list in the last decade. The geometric growth of the energy efficiency is offset by a geometric growth of the peak computation power. This results in a moderate growth in power consumption.
The same is true for data-centers, for which increases in demand are balanced by efficiency gains, producing a net power increase of 6% from 2010 to 2018 [15]. All in all, despite large efficiency gains, the net effect is an increase in carbon emissions.
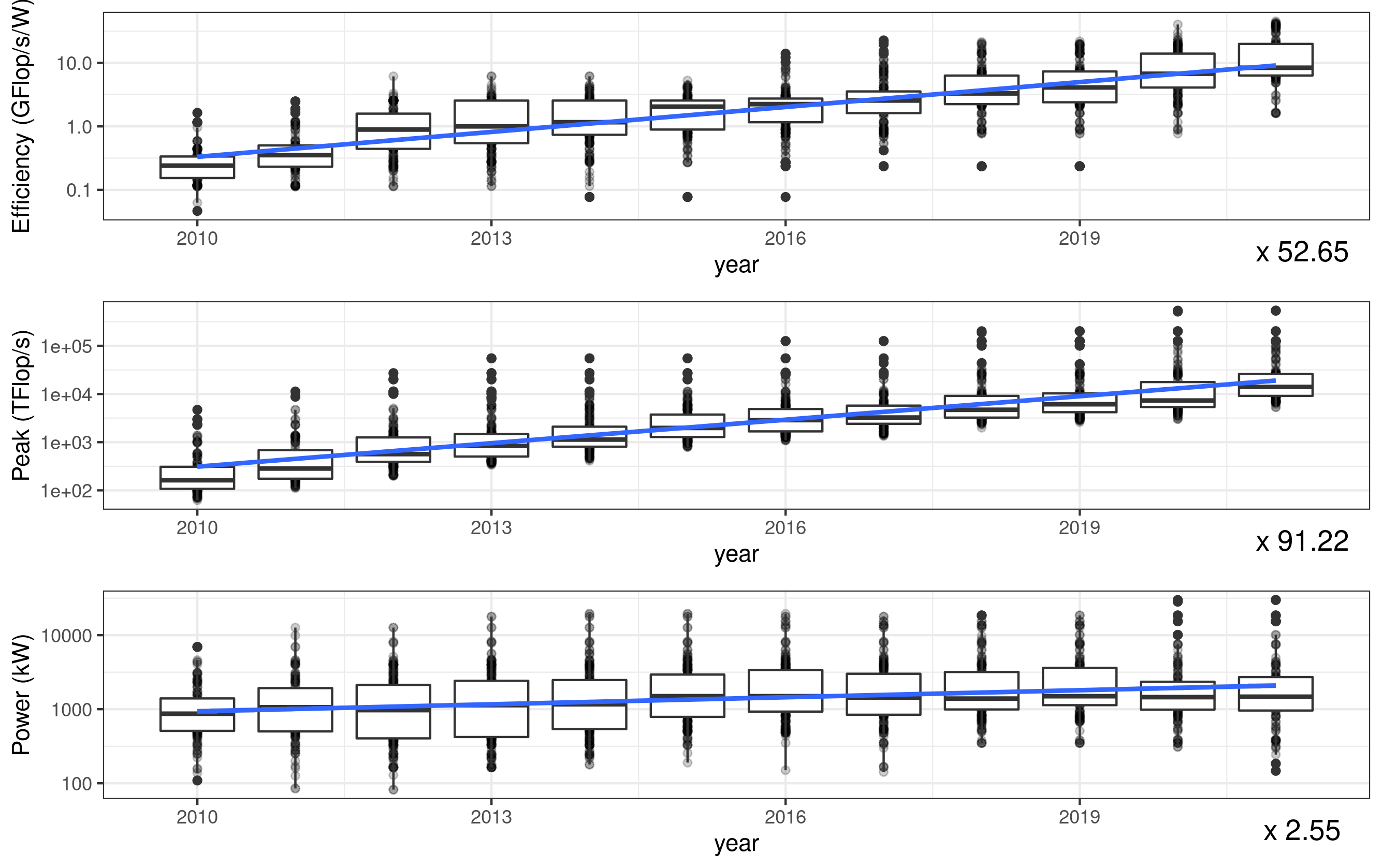
In the last decade, the growth of the total power consumption has been moderate. But with the slowing down of CMOS scaling, there is a risk that the efficiency improvements in processors will reach a limit [6]. In that scenario, increases in computation volume would directly translate into higher energy consumption and carbon emissions.
Few studies directly quantify the indirect and economy-wide rebound effects of ICT. Yet, in its last report [24], the ICPP working group III recognizes rebound effects in digitalization as a risk towards carbon emissions increase since they “have the potential to steeply increase energy efficiency in all end-use sectors through material input savings and increased coordination. […] economic growth resulting from higher energy and labour productivities can increase energy demand and associated GHG [Green House Gas] emissions. Importantly, digitalization can also benefit carbon-intensive technologies”.
Computation sobriety: when less is more
In computer simulations, efficiency gains are often leveraged to increase model complexity or size. Much like in Jevons’ paradox, efficiency gains can increase computation and data storage capacity demands.
For example, Neural Networks have received many optimizations in the last decade. Codes have been optimized to run on GPU and, later, on dedicated architectures such as Google Tensor Processing Unit. Algorithms and data representations have been optimized [25]. For example, networks exploit smaller floating-point formats, such as bfloat16, to reduce bandwidth, computation time, and storage size.
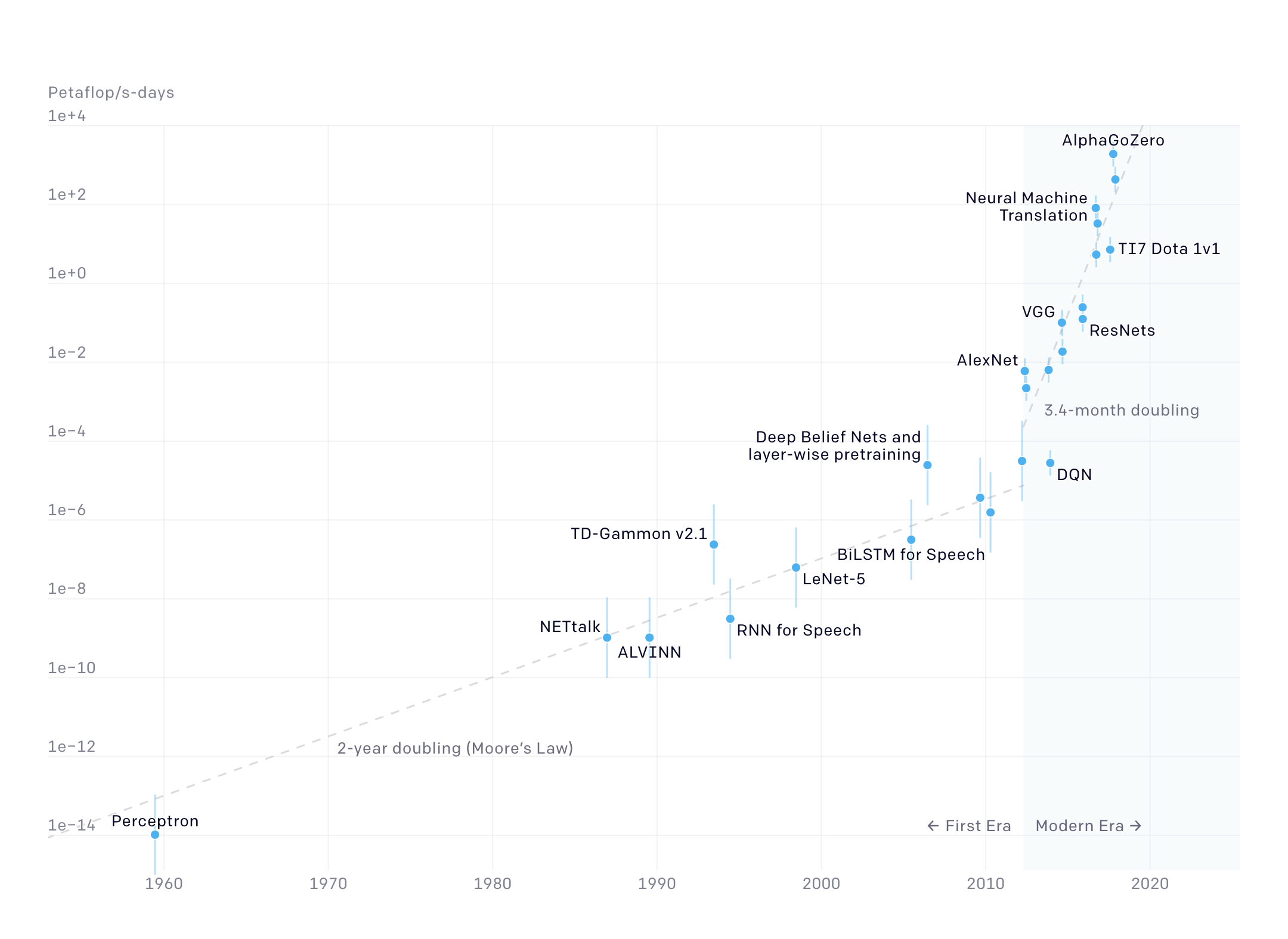
Despite the optimizations, the training cost of neural networks has spiked [27]. Figure 2 shows that from 2012 onwards, the training cost for AI systems doubles every 3.4 months. The training cost from 2012 to 2018 has grown by a × 300 000 factor.
Schwartz et al. [8] studies different generations of image recognition neural networks. In figure 3, Schwartz compares the accuracy, the training cost, and the number of parameters. The accuracy, expressed as a percentage, is the success rate in an object recognition task. The training cost is measured as the number of floating-point operations used during training. The number of model parameters is also reported.
Schwartz et al. [8] show that there are diminishing returns on accuracy. The accuracy gains are marginal for a linear increase in computation power and model complexity.
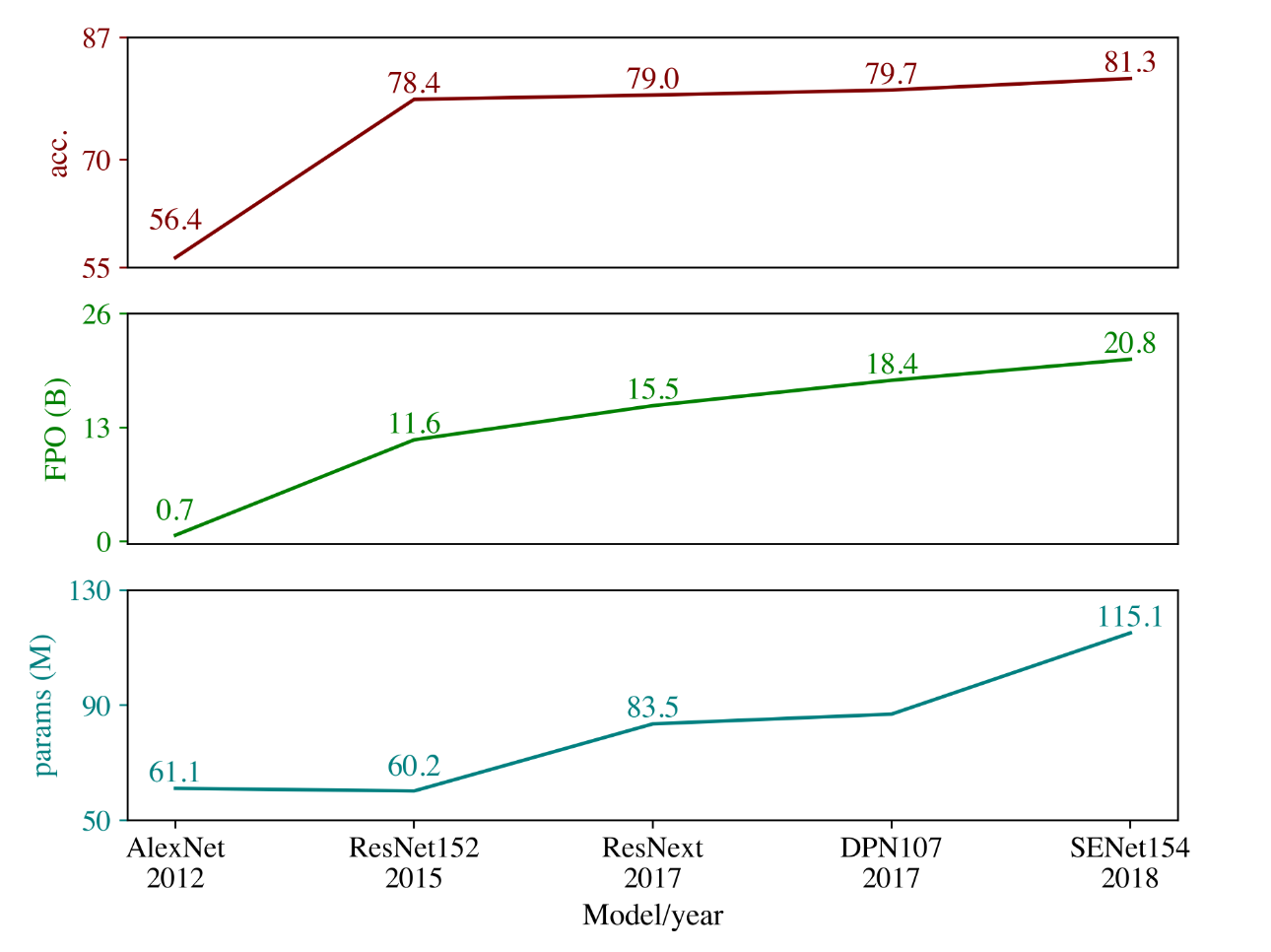
Schwartz shows that in the last decade, linear accuracy gains have required an exponential increase in model complexity and computation cost. Such as trend appears unsustainable. It appears necessary to weigh higher accuracy’s benefits against the increased computation cost. Since the needed accuracy depends on the model finality, it is difficult to draft general guidelines. Nevertheless, Schwartz et al.[8] advocate for systematically reporting the model efficiency, such as the total FLOP or energy used during training, alongside the accuracy. Considering an efficiency metric makes it possible to select the smallest model satisfying the target accuracy.
Case study in healthcare
To illustrate the previous discussion with a concrete case study, I turn to the work of Dacremont [28] and her colleagues at the Swiss Tropical and Public Health Institute. They have developed e-POCT, an algorithm for the management of febrile illnesses in resource-limited countries [29]. D’Acremont discusses the diminishing returns of AI models when applied to healthcare.
e-POCT uses Classification and Regression Trees to help diagnose Tanzanian children with febrile illnesses and recommends adequate treatment. e-POCT is embedded on an Android tablet which gathers data from different sources: objective measures from an oxymeter, hemoglobinometer and glucometer; Point of Care (POC) tests for Malaria or VIH; clinical signs observed by the treating clinician. The algorithm follows the classification tree step-by-step, suggesting tests to perform and, when reaching a leaf establishing a diagnosis, recommending treatment, or referring the patient for higher-level care. In a randomized trial in Tanzania with 1 586 children, e-POCT improved clinical outcomes while reducing antibiotic prescription from 30% to 11%.
The World Health Organization has produced the Integrated Management of Childhood Illness (IMCI), a strategy to help treat children’s illnesses in resource-limited countries. Interestingly, IMCI contains paper-based classification trees similar to the ones produced by e-POCT. Yet unlike the IMCI classification tree, e-POCT algorithm is tailored and trained using real data, which reflects the statistical prevalence of diseases in Tanzania [30]. This training allows fitting the CART model to the target population.
After an initial successful field trial for e-POCT, the development continues in the DYNAMIC [31] Study, which would deploy a more sophisticated AI systems to continuously collect patient data and adapt the algorithm. Such a solution incurs higher carbon emissions because it requires more computing power and increases the amount of data collected and transmitted.
There seems to be a law of diminishing returns at play. On the low end of the technology spectrum, we have paper-based classification algorithms like the ones proposed in IMCI. In the middle, we have the tablet-based e-POCT algorithm, where the algorithm is static and updated manually. At the high end of the spectrum, we have sophisticated AI algorithms that require dedicated HPC servers and continuous data collection.
Developing countries are strongly affected by climate change. Among other problems, droughts, floods, or air pollution caused by the environmental crisis negatively affect the health of children in Africa. Fabricating the tablets used for e-POCT currently involves child labor in rare-earth mines where children are exposed to pollutants. Dacremont [28] wonders if the increased accuracy of diagnosis with the more sophisticated solutions would justify the increased carbon emissions.
A first step to guide the technical choice would require precisely quantifying the environmental impact of the different solutions by estimating the power consumption and performing a life-cycle assessment of the hardware involved. This impact should be weighed against the potential improvements in healthcare that each solution brings and how well the local clinicians and patients will accept the technology. Choosing an appropriate model involves complex social and environmental factors and requires considering all ethical factors.
Closing thoughts
D’Acremont study perfectly illustrates the dilemma of choosing the right complexity for a computation model and shows that the most accurate and advanced technological solution is not necessarily the better one when all factors are considered.
The field of HPC offers many choices and avenues for optimization. First, we choose the physical phenomena to model and the finesse of the discretization. Then, we select a target machine that will execute the program. Finally, we write an implementation algorithm and apply different optimizations at the level of the programming language, the compiler, or the operating system. Usually, this process is not sequential and requires back-and-forths to find a good fit between the model, the implementation, and the architecture.
Despite significant optimizations targeting the model, the software, and the hardware; the demand for computation keeps rising. Indeed, the efficiency gained is harnessed to increase the model complexity. Curbing HPC power consumption might not be a technical issue but a methodological one. Like D’Acremont, we need to consider how many resources we dedicate to a given computation. It is not possible to answer this question in general. The allocated resources must be weighed against the expected requirements and outcomes for the computation, which are specific, contextual, and political questions.
Yet remaining general, we can question the tendency to always go for the more complex or accurate model. Going for the most accurate model is a shortcut that saves us from thinking about the fit between the model and our research question. Yet, I believe that questioning this fit before running the computation would help us reduce the size of models and increase the quality of our research. For example, in image recognition, there is a tendency nowadays to go for DNNs regardless of the problem because of their flexibility. In many cases [32], thinking about the structure of the problem beforehand allows using classical computer-vision methods that are as efficient and less costly.
Simulation has changed the way we do science, creating a new epistemological tool that stands between experiment and theory, and bringing incredible scientific advances in many fields. However, faced with a shrinking energy budget, we should carefully consider when simulation is needed and not use it blindly. After all, the most environmentally friendly code is the one that is not run.
Bibliography
1 Oliveira Castro, Pablo de (2022) ‘High Performance Computing code optimizations: Tuning performance and accuracy’. [online] Available from: https://tel.archives-ouvertes.fr/tel-03831483/
2 Lebbie, Tamba S., Moyebi, Omosehin D., Asante, Kwadwo Ansong, Fobil, Julius, et al. (2021) ‘E-waste in africa: A serious threat to the health of children’. International Journal of Environmental Research and Public Health, 18(16), p. 8488.
3 Masson-Delmotte, Valérie, Zhai, Panmao, Pirani, Anna, Connors, Sarah L, et al. (2021) ‘Climate change 2021: The physical science basis. Contribution of working group i to the sixth assessment report of the intergovernmental panel on climate change.’
4 Jones, Nicola (2018) ‘How to stop data centres from gobbling up the world’s electricity’. Nature, 561(7722), pp. 163–167.
5 Freitag, Charlotte, Berners-Lee, Mike, Widdicks, Kelly, Knowles, Bran, et al. (2021) ‘The real climate and transformative impact of ICT: A critique of estimates, trends, and regulations’. Patterns, 2(9), p. 100340. [online] Available from: https://www.sciencedirect.com/science/article/pii/S2666389921001884
6 Freitag, Charlotte, Berners-Lee, Mike, Widdicks, Kelly, Knowles, Bran, et al. (2021) ‘The climate impact of ICT: A review of estimates, trends and regulations’. [online] Available from: https://arxiv.org/abs/2102.02622
7 Hannah Ritchie, Max Roser and Rosado, Pablo (2020) ‘CO2 and greenhouse gas emissions’. Our World in Data. [online] Available from: https://ourworldindata.org/co2-and-other-greenhouse-gas-emissions
8 Schwartz, Roy, Dodge, Jesse, Smith, Noah A. and Etzioni, Oren (2019) ‘Green AI’. arXiv:1907.10597 [cs, stat]. [online] Available from: http://arxiv.org/abs/1907.10597 (Accessed 3 February 2021)
9 Patterson, David, Gonzalez, Joseph, Le, Quoc, Liang, Chen, et al. (2021) ‘Carbon emissions and large neural network training’. arXiv:2104.10350 [cs]. [online] Available from: http://arxiv.org/abs/2104.10350 (Accessed 7 June 2021)
10 RTE (2021) Futurs énergétiques 2050 - principaux résultats,
11 Koomey, Jonathan, Berard, Stephen, Sanchez, Marla and Wong, Henry (2010) ‘Implications of historical trends in the electrical efficiency of computing’. IEEE Annals of the History of Computing, 33(3), pp. 46–54.
12 Borkar, Shekhar and Chien, Andrew A (2011) ‘The future of microprocessors’. Communications of the ACM, 54(5), pp. 67–77.
13 Schöne, Robert, Ilsche, Thomas, Bielert, Mario, Velten, Markus, et al. (2021) ‘Energy efficiency aspects of the AMD zen 2 architecture’, in 2021 IEEE international conference on cluster computing (CLUSTER), IEEE, pp. 562–571.
14 Su, Lisa T, Naffziger, Samuel and Papermaster, Mark (2017) ‘Multi-chip technologies to unleash computing performance gains over the next decade’, in 2017 IEEE international electron devices meeting (IEDM), IEEE, pp. 1–1.
15 Masanet, Eric, Shehabi, Arman, Lei, Nuoa, Smith, Sarah and Koomey, Jonathan (2020) ‘Recalibrating global data center energy-use estimates’. Science, 367(6481), pp. 984–986.
16 Liu, Yongpeng and Zhu, Hong (2010) ‘A survey of the research on power management techniques for high-performance systems’. Software: Practice and Experience, 40(11), pp. 943–964.
17 Wysocki, Rafael J. (n.d.) ‘CPU performance scaling — the linux kernel documentation’. [online] Available from: https://www.kernel.org/doc/html/v5.18/admin-guide/pm/cpufreq.html (Accessed 23 May 2022)
18 Stoffel, Mathieu and Mazouz, Abdelhafid (2018) ‘Improving power efficiency through fine-grain performance monitoring in HPC clusters’, in 2018 IEEE international conference on cluster computing (CLUSTER), IEEE, pp. 552–561.
19 André, Etienne, Dulong, Remi, Guermouche, Amina and Trahay, François (2022) ‘DUF: Dynamic uncore frequency scaling to reduce power consumption’. Concurrency and Computation: Practice and Experience, 34(3), p. e6580.
20 Pereira, Rui, Couto, Marco, Ribeiro, Francisco, Rua, Rui, et al. (2017) ‘Energy efficiency across programming languages: How do energy, time, and memory relate?’, in Proceedings of the 10th ACM SIGPLAN international conference on software language engineering, Vancouver BC Canada, ACM, pp. 256–267. [online] Available from: https://dl.acm.org/doi/10.1145/3136014.3136031
21 Pallister, James, Hollis, Simon J and Bennett, Jeremy (2015) ‘Identifying compiler options to minimize energy consumption for embedded platforms’. The Computer Journal, 58(1), pp. 95–109.
22 Gossart, Cédric (2015) ‘Rebound effects and ICT: A review of the literature’. ICT innovations for sustainability, pp. 435–448.
23 Hilty, Lorenz, Lohmann, Wolfgang and Huang, Elaine M (2011) ‘Sustainability and ICT-an overview of the field’. Notizie di POLITEIA, 27(104), pp. 13–28.
24 Shukla, P. R., Skea, J., Slade, R., Khourdajie, A. Al, et al. (2022) ‘Mitigation of climate change. Contribution of working group III to the sixth assessment report of the intergovernmental panel on climate change’.
25 Capra, Maurizio, Bussolino, Beatrice, Marchisio, Alberto, Masera, Guido, et al. (2020) ‘Hardware and software optimizations for accelerating deep neural networks: Survey of current trends, challenges, and the road ahead’. IEEE Access, 8, pp. 225134–225180.
26 Amodei, Dario, Hernandez, Danny, Sastry, Girish, Clark, Jack, et al. (2018) ‘AI and compute. OpenAI’. [online] Available from: https://openai.com/blog/ai-and-compute/ (Accessed 30 May 2022)
27 Trystram, Denis, Couillet, Romain and Ménissier, Thierry (2021) ‘Apprentissage profond et consommation énergétique : La partie immergée de l’IA-ceberg. The conversation’. [online] Available from: http://theconversation.com/apprentissage-profond-et-consommation-energetique-la-partie-immergee-de-lia-ceberg-172341 (Accessed 30 May 2022)
28 D’Acremont, Valérie (2021) ‘Santé, technologies, environnement : Quels compromis éthiques ?’ [online] Available from: https://youtu.be/oKcy_cY0QOw
29 Keitel, Kristina, Kagoro, Frank, Samaka, Josephine, Masimba, John, et al. (2017) ‘A novel electronic algorithm using host biomarker point-of-care tests for the management of febrile illnesses in tanzanian children (e-POCT): A randomized, controlled non-inferiority trial’. PLOS Medicine, 14(10), pp. 1–29. [online] Available from: https://doi.org/10.1371/journal.pmed.1002411
30 Santis, Olga De, Kilowoko, Mary, Kyungu, Esther, Sangu, Willy, et al. (2017) ‘Predictive value of clinical and laboratory features for the main febrile diseases in children living in tanzania: A prospective observational study’. PLOS ONE, 12(5), p. e0173314. [online] Available from: https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0173314 (Accessed 10 May 2022)
31 Dynamic Study (2022) ‘Project web page’. [online] Available from: https://dynamic-study.com/
32 O’Mahony, Niall, Campbell, Sean, Carvalho, Anderson, Harapanahalli, Suman, et al. (2019) ‘Deep learning vs. Traditional computer vision’, in Science and information conference, Springer, pp. 128–144.